Deep Learning
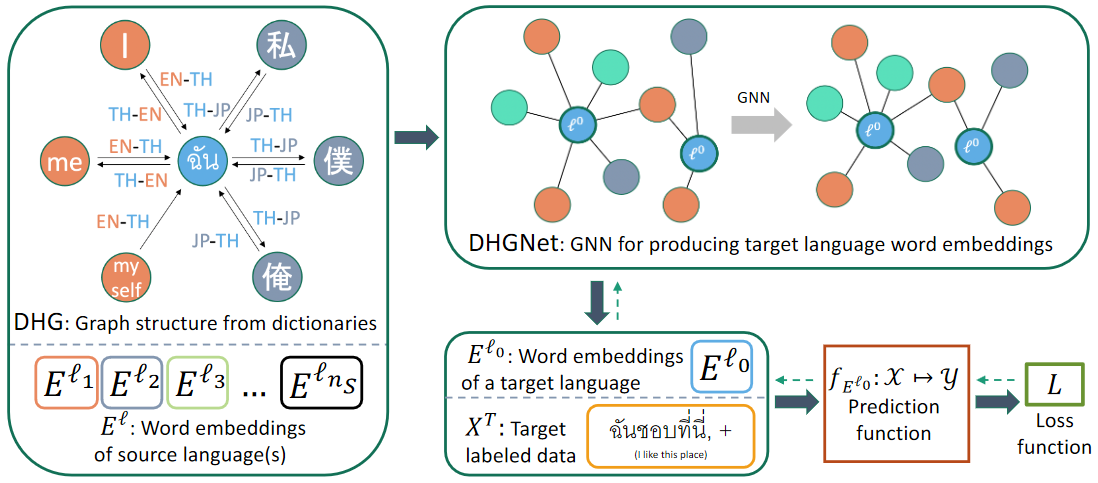
Cross-linguistic text classification is transfer learning that uses training data from resource-rich languages to solve classification problems in resource-poor languages. In cross-lingual text classification, it is required that task-specific training data in high resource source languages are available, where the task is identical to that of a low-resource target language. However, collecting such training data can be infeasible because of the labeling cost, task characteristics, and privacy concerns. This paper proposes an alternative solution that uses only task-independent word embeddings of high-resource languages and bilingual dictionaries.
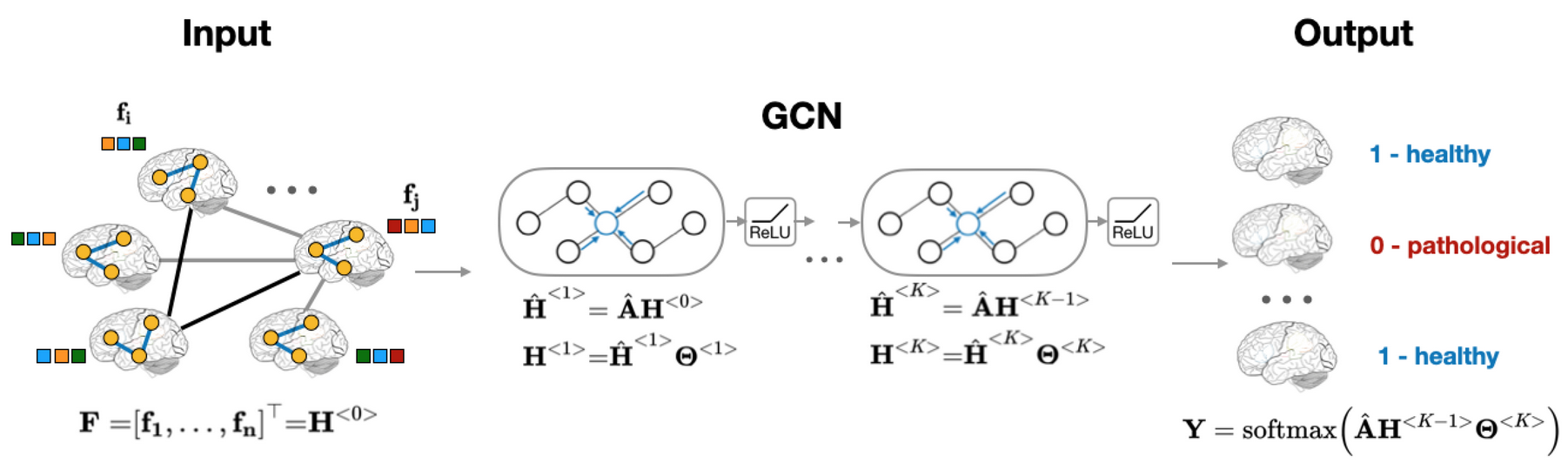
With the advancement of brain imaging techniques and a variety of machine learning methods, significant progress has been made in brain disorder diagnosis, in particular Autism Spectrum Disorder. The development of machine learning models that can differentiate between healthy subjects and patients is of great importance. The application of graphs for analyzing brain imaging datasets helps to discover clusters of individuals with a specific diagnosis. However, the choice of the appropriate population graph becomes a challenge in practice, as no systematic way exists for defining it. To solve this problem, we propose a population graph-based multi-model ensemble, which improves the prediction, regardless of the choice of the underlying graph. First, we construct a set of population graphs using different combinations of imaging and phenotypic features and evaluate them using Graph Signal Processing tools. Subsequently, we utilize a neural network architecture to combine multiple graph-based models. The results demonstrate that the proposed model outperforms the state-of-the-art methods on Autism Brain Imaging Data Exchange (ABIDE) dataset.
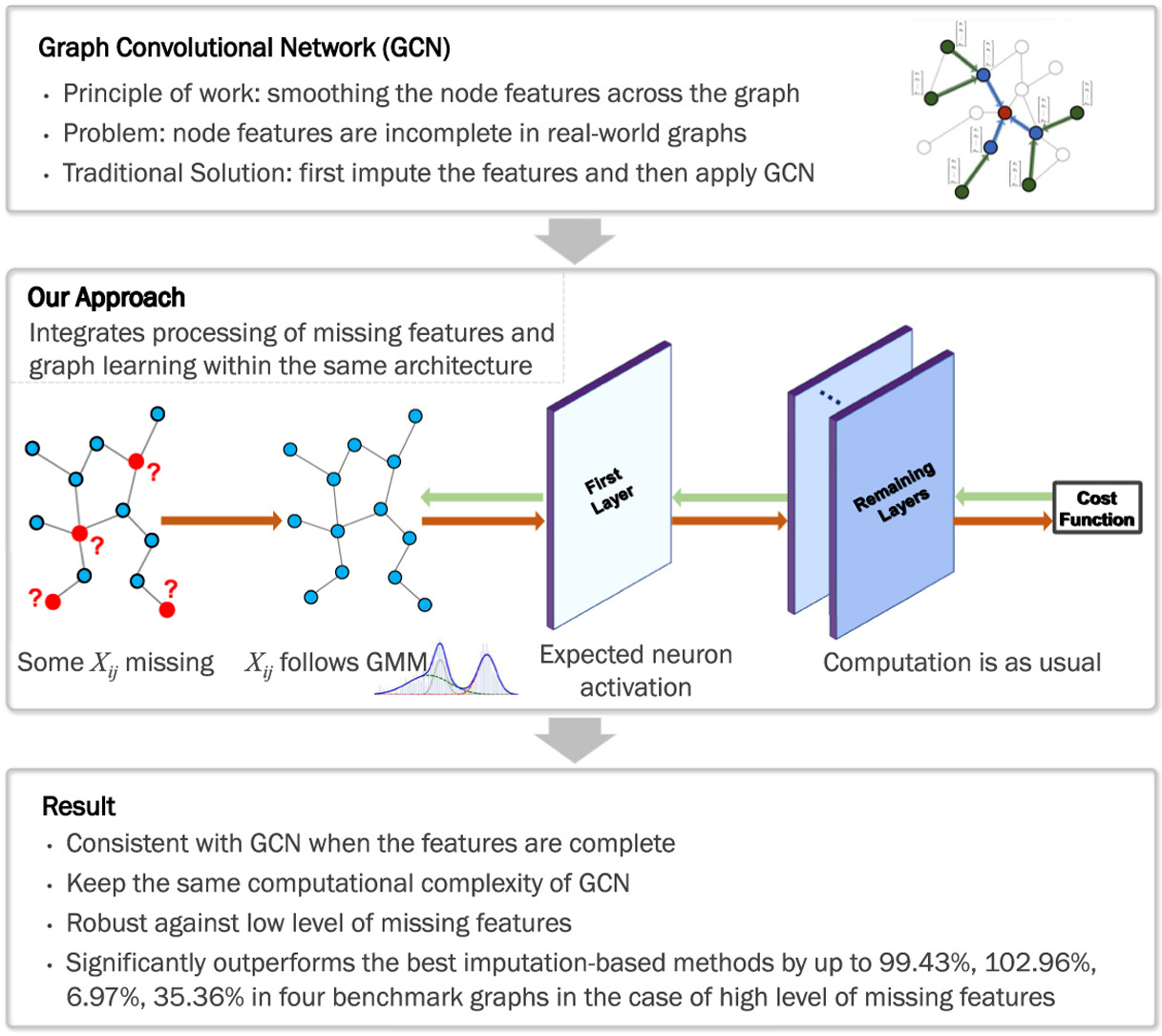
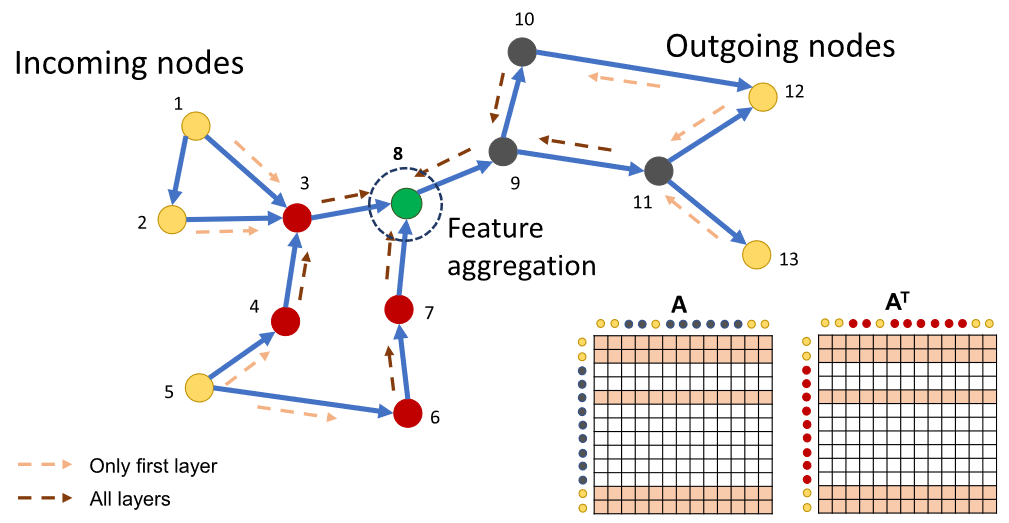
Graph Convolutional Network (GCN) works by smoothing the node features across the graph. The current GCN models overwhelmingly assume that the node feature information is complete. However, real-world graph data are often incomplete and containing missing features. Traditionally, people have to estimate and fill in the unknown features based on imputation techniques and then apply GCN. However, the process of feature filling and graph learning are separated, resulting in degraded and unstable performance. We propose an approach that adapts GCN to graphs containing missing features. In contrast to traditional strategy, our approach integrates the processing of missing features and graph learning within the same neural network architecture. Our idea is to represent the missing data by Gaussian Mixture Model (GMM) and calculate the expected activation of neurons in the first hidden layer of GCN, while keeping the other layers of the network unchanged. This enables us to learn the GMM parameters and network weight parameters in an end-to-end manner. Notably, our approach does not increase the computational complexity of GCN and it is consistent with GCN when the features are complete. We demonstrate through extensive experiments that our approach significantly outperforms the imputation based methods in node classification and link prediction tasks. We show that the performance of our approach for the case with a low level of missing features is even superior to GCN for the case with complete features.
Betweenness centrality and closeness centrality are two commonly used node ranking measures to find out influential nodes in the graphs in terms of information spread and connectivity. Both of these are considered as shortest path based measures as the calculations require the assumption that the information flows between the nodes via the shortest paths. However, exact calculations of these centrality measures are computationally expensive and prohibitive, especially for large graphs. We propose the first graph neural network (GNN) based model to approximate betweenness and closeness centrality. In GNN, each node aggregates features of the nodes in multihop neighborhood. We use this feature aggregation scheme to model paths and learn how many nodes are reachable to a specific node. We demonstrate that our approach significantly outperforms current techniques while taking less amount of time through extensive experiments on a series of synthetic and real-world datasets. A benefit of our approach is that the model is inductive, which means it can be trained on one set of graphs and evaluated on another set of graphs with varying structures. Thus, the model is useful for both static graphs and dynamic graphs. Source code is available at https://github.com/sunilkmaurya/GNN_Ranking
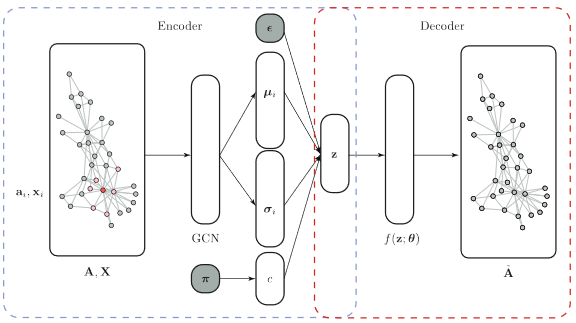
Variational autoencoder (VAE) is one of the models of deep learning. It learns generative models for classification and for generation of similar synthetic entities. We focus on variational graph autoencoder (VGAE), the extension of VAE to graph structures. In VGAE, Graph Convolutional Network is used for encoder, and inner product is used for decoder. We propose Variational Graph Autoencoder for Community Detection (VGAECD), a new generative model which encodes graph structures with multiple Gaussian distributions corresponding to each of the communities in a network. We show the effectiveness of proposed VGAECD by comparing the accuracies of community detection with those of other related methods.
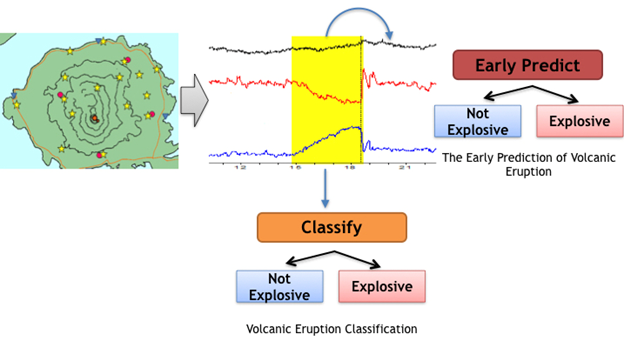
Deep learning recently has shown advantages in a variety of applications such as speech recognition, image recognition, and natural language processing. However, there was relatively little work exploring feature learning in time sensitive applications. In this research, we would like to take advantages of deep learning into typical time series data and practically apply this technique to sensor data acquired from volcanic monitors. The sensor time series data obtained from the monitoring system has a strong correlation with the current and future eruption, but the data is rather complicated and hard to be analyzed even by the experts. Therefore we proposed two problems: Volcanic Eruption Classification and The Early Prediction of Volcanic Eruption. The goal of Volcanic Eruption Classification is to recognize the current status of the volcano, while The Early Prediction of Volcanic Eruption predicts the future eruption by detecting the time series prior to the eruption which is the early signal of the upcoming eruption. The proposed Multimodal Fusion VolNet based on Convolutional Neural Network for Volcanic Eruption Classification achieves an average F-score of 90%. For The Early Prediction of Volcanic Eruption, the proposed PredictNet based on Attentional Stacked Long Short-Term Memory achieves promising results of 66% sensitivity and the accuracy of the warning system of 64% in the critical stage. We demonstrate the effectiveness of our methods on the largest and the most comprehensive set of volcano sensor time series data experiments ever conducted.
Link Mining
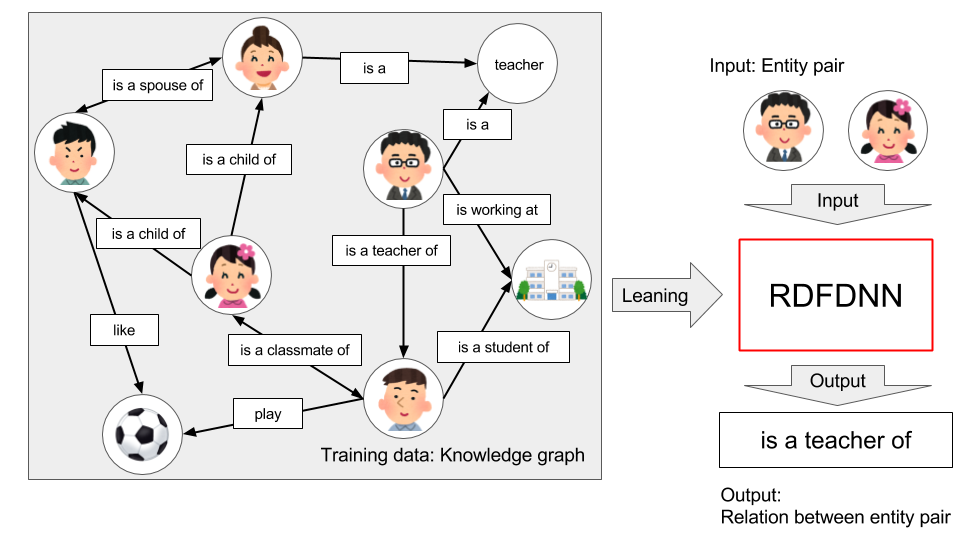
Predicting relations between words is important for building large-scale Semantic Web such as Knowledge Graph. We have developed Deep Neural Network (called RDFDNN) for the purpose of accurate prediction of relations between given subject and object in Resource Description Framework(RDF). RDFDNN predicts relations more accurately than previous methods such as TransE and TransR.
Codes are available in GitHub.
We propose a method for transductive classification on heterogeneous networks composed of multiple types of vertices (such as papers, authors and conferences). When a network and the labels of some vertices are given, transductive classification is used to classify the labels of the remaining vertices. Based on novel definition of edge betweenness for heterogeneous networks, our method gained around 5% increase in accuracy from the state-of-the-art methods including GNetMine.
Many automatic methods for community detection have been already proposed. If we can utilize background knowledge of node similarity or dissimilarity in a network, more convincing communities will be detected. Eaton et al. proposed a method for constrained community detection which optimizes constrained Hamiltonian. But their method is slow for large-scale networks because they employ simulated annealing. Our method uses Louvain method for optimizing constrained Hamiltonian and it accelerates constrained community detection greatly.
Influence maximization involves a problem of finding a set of nodes that will propagate information or disease most in given social networks. Many previous methods search for nodes of high centrality, which are not always good for this problem. Finding strict solution for the problem is computationally intractable even for static networks. This research employs greedy algorithm and heuristics for influence maximization in dynamic social networks. Our method is much faster than previous methods, and the accuracies of its solutions are not inferior to strict solutions.
YouTube can be regarded as a network of videos, users and tags. Many social media can be represented as heterogeneous networks that contain relations among many types of nodes and edges. We invented a method for detecting communities of tripartite networks that contain three types of nodes.
A signed network contains two types of edges: friendship and hostility. We extend modularity (a criteria for evaluating goodness of network partitions) for signed networks so that we can detect nested factions, which often appears in real social networks.
People nearby tend to be close friends. We propose Dist-Modularity, an extension of Girvan-Newman modularity, in order to exclude such tendency. Dist-Modularity are useful for detecting communities whose members are far apart, and it has abilities of detecting communities of different granularity.
Dist-Modularity is used for detecting terrorist networks by the researchers of U.S. Military Academy.
Many real-world networks exhibit scale-free property. We propose a method for detection communities from such scale-free networks.

Great speeches are semantically well-structured, and they are often studied as a good example for writing compositions. As the first step for evaluating the quality of a given speech, we propose a method for visualizing the speech structure using WordNet (a dictionary of semantic relations of English words) and semantic orientation (positiveness or negativeness of words).
 poster is available here
poster is available here
Web Usage Mining
When a user accesses to the Web, several usage data are generated such as access logs, bookmarks, and searched keywords. We are doing research on detecting the user's interests base on the usage data.- Extracting Users' Interests from Web Usage Data
- We have proposed a new method for extracting a user's interests based on the network of the sites he/she visited and the keywords he/she entered, which we call a site-keyword graph. In our experiments, ranking and community detection are performed to the site-keyword graphs of 8,000 users in order to detect their interests.
- Tsuyoshi Murata and Kota Saito, "Extracting Users' Interests of Web-watching Behaviors Based on Site-Keyword Graph", in A. Namatame, S. Kurihara, H. Nakashima, (Eds.), Emergent Intelligence of Networked Agents, Studies in Computational Intelligence, Vol.56, pp.139-146, Springer, 2007.
-