深層学習
言語横断テキスト分類は資源が豊富な言語の訓練データを使って、資源が乏しい言語の分類問題を解くための転移学習です。 言語横断テキスト分類では、資源が乏しい言語でのタスクに特化した、資源が豊富な言語のタスク固有の訓練データ を用意することが必要です。しかし、このような訓練データを収集することは、ラベリングコスト、タスクの特性、 プライバシーへの配慮などの理由から実現不可能な場合があります。この研究では,資源が豊富な言語のタスクに依存しない 単語埋め込みと2言語間の辞書のみを用いた言語横断テキスト分類を提案します。
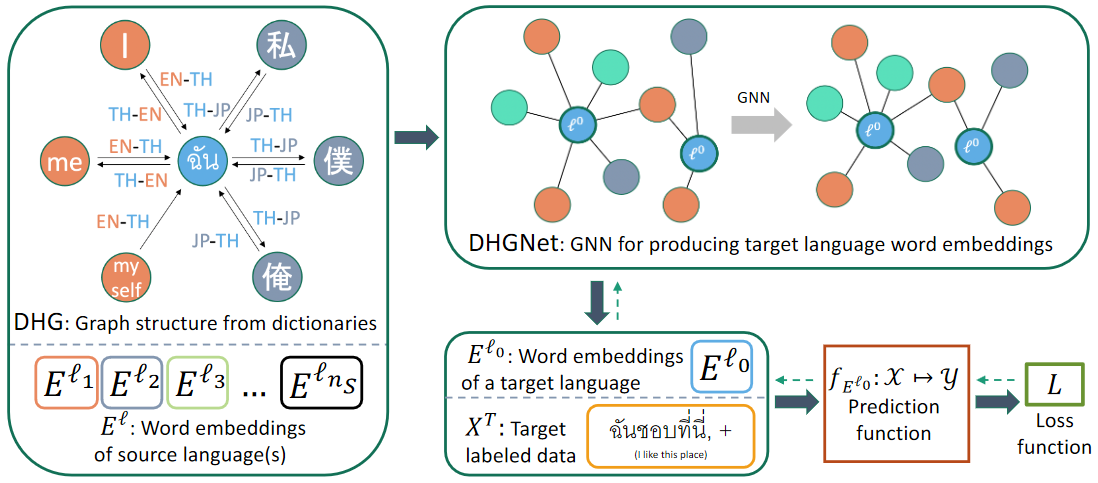
救急医療サービス(Emergency Medical Service: EMS)は、生命を脅かす緊急事態の被害者に応急処置を施すことで、生存率の 向上に不可欠な役割を果たしています。しかし大都市におけるEMSの需給バランスが悪いと、アクセス可能なEMS資源が不足し、 応急処置が遅れる可能性があります。隠れたEMS需給関係を明らかにし、来るべきEMS需要を予測し、予想外の緊急事態に備える ことが急務です。この研究では、EMS需要が人口統計データ、地域の社会経済的要因、病院の状況と相関していると仮定します。 これらの相関要因をモデル化するために、東京都の救急車の記録データを病院-地域の2部グラフで表現し、病院-地域のペア間の 救急需要を予測する2部グラフ畳み込みニューラルネットワークモデルを提案します。我々のアプローチは、2つの需要ラベルの 予測タスクにおいて77.3%~87.7%の精度を達成しました。これは、従来の機械学習アルゴリズム、統計モデル、および最新の グラフベースの手法を大幅に上回るものです。最後に、EMS需要予測の重要性を示すためにケーススタディを行い、我々のアプ ローチがEMS予測を行うことで公衆衛生の緊急管理に貢献できることを示しました。
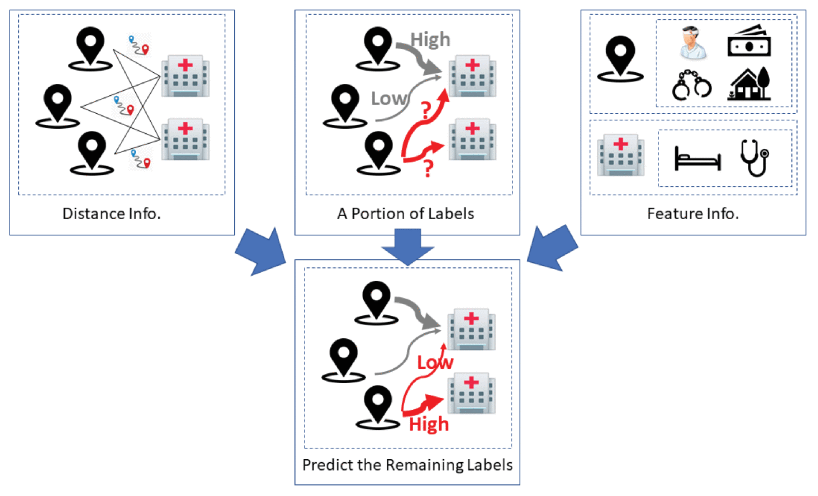
脳画像技術や様々な機械学習手法の進歩により、脳疾患の診断、特に自閉症スペクトラム障害の診断に大きな進歩が見られます。 そのため、健常者と患者を区別できる機械学習モデルの開発は非常に重要です。グラフを脳画像データの解析に適用することで、 特定の診断を受けた個人のクラスタを発見することができます。しかし、適切なpopulation graphを選択することは、体系的な 方法が存在しないため、実際には困難です。この問題を解決するために,本研究では,population graphに基づくマルチモデル アンサンブルを提案します.まず、画像と表現型の特徴の異なる組み合わせを用いてpopulation graphの集合を構築し、グラフ 信号処理ツールを用いて評価します。続いて、ニューラルネットワークアーキテクチャを利用して、複数のグラフベースのモデル を組み合わせます。その結果、提案モデルは、Autism Brain Imaging Data Exchange (ABIDE)データセットにおいて、最先端の 手法よりも優れていることが示されました。
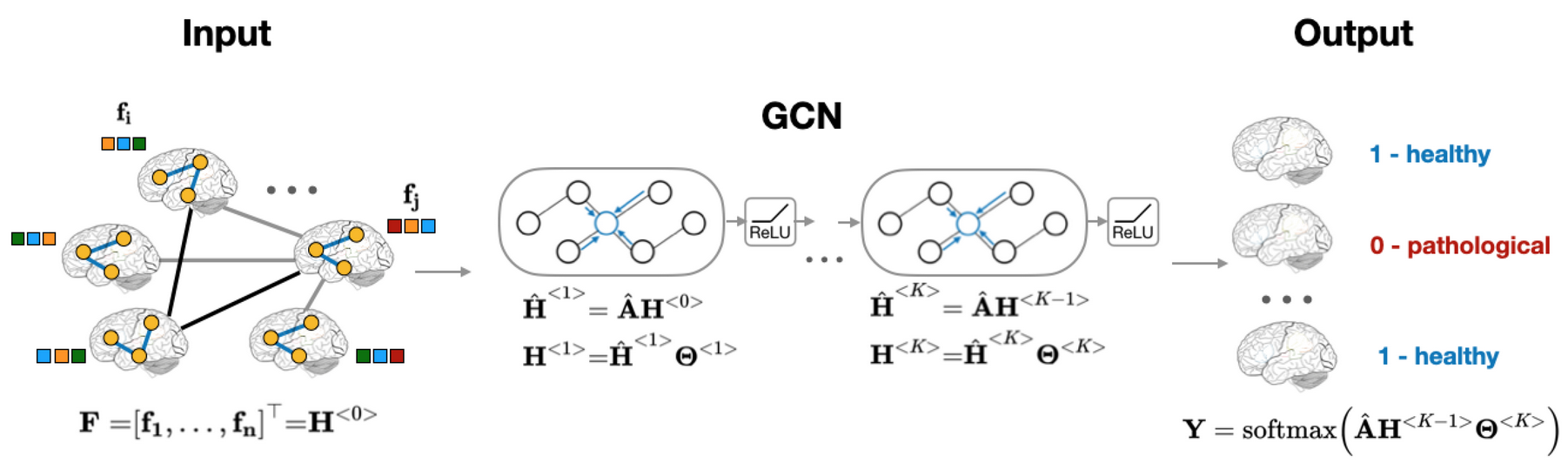
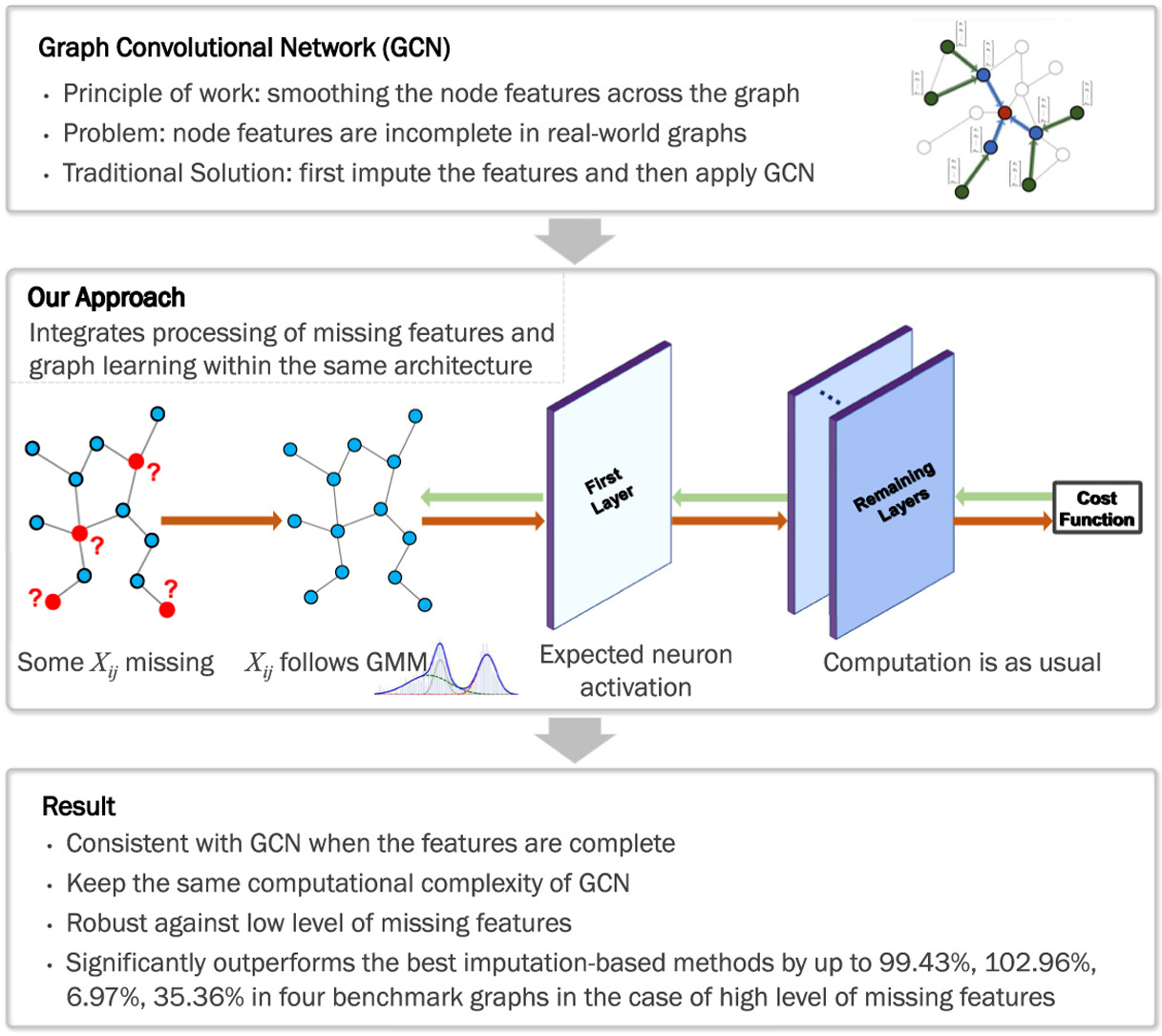
グラフ畳み込みネットワーク(Graph Convolutional Network: GCN)は、グラフ上のノードの特徴を平滑化することで動作します。 現在のGCNモデルの多くは、ノード特徴の情報が完全であることを前提としています。しかし現実のグラフデータは、特徴量の欠損を 含む不完全なものが多いです。従来は、補完技術に基づいて未知の特徴を推定して埋めてからGCNを適用していましたが、特徴量の補完 とグラフ学習のプロセスが分離しているため、性能が低下し不安定になってしまいます。この研究では、GCNを欠損した特徴を含む グラフに適応させるアプローチを提案します。従来の手法とは対照的に、我々のアプローチでは、欠損特徴の処理とグラフ学習を同じ ニューラルネットワークアーキテクチャ内に統合します。欠損データを混合ガウスモデル(GMM)で表現し、GCNの第一隠れ層のニューロン の期待される活性化を計算し、、ネットワークのそれ以外の層は変更しません。これにより,GMMのパラメータとネットワークの重み パラメータをエンド・ツー・エンドで学習することができます。注目すべきことは,我々のアプローチがGCNの計算量を増加させず, また,特徴量が完成したときにGCNと一貫性があることです。我々のアプローチは,ノード分類とリンク予測のタスクにおいて,補完に 基づく手法を大幅に上回ることを,幅広い実験を通して示しました.また,欠損が少ない場合の本手法の性能は,欠損がない場合の GCNよりも優れていることを示しました.
媒介中心性と近接中心性は、情報拡散と結合性の観点から、グラフ内で影響力のある頂点を見つけるためによく用いられる2つの中心性です。これらはいずれも、頂点間の情報の流れが最短パスを経由するという前提で計算されるため、最短パスベースの尺度と考えられます。しかし、これらの中心性指標の厳密な計算は、特に大規模なグラフの場合、計算コストが非常に高いです。 この研究では、グラフニューラルネットワーク(GNN)を用いて、媒介中心性と近接中心性を近似する初めてのモデルを提案しました。 GNNでは、各頂点がマルチホップの近傍の頂点の特徴を集約します。この特徴集約スキームを用いてパスをモデル化し、特定のノードに到達可能なノードの数を学習します。 我々のアプローチは、一連の人工データおよび実世界のデータセットを用いた広範な実験により、より少ない時間で既存の技術を大幅に上回ることを示しました。我々のアプローチの利点は、モデルが帰納的であることです。つまり、あるグラフセットで学習し、構造が異なる別のグラフセットで評価することができます。したがって、このモデルは、静的なグラフと動的なグラフの両方に有効です。 ソースコードは https://github.com/sunilkmaurya/GNN_Ranking にあります。
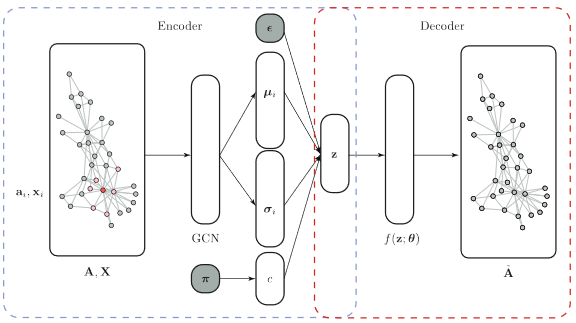
variational autoencoder (VAE)は深層学習におけるモデルの一つであり、画像認識などにおいて画像 の生成モデルを学習することによって、画像の分類をしたり、与えられた画像に似た人工的な画像を生成 したりすることが可能になります。この考え方をグラフ構造に応用したvariational graph autoencoder (VGAE) に注目します。VGAEにおいては、encoderとしてはGraph Convolutional Networkを用い、decoderとしては 内積を用いています。本研究では、ネットワーク中の複数のコミュニティに対応する複数のGaussianの分布に よってグラフ構造をencodeするネットワーク生成モデルvariational graph autoencoder for community detection (VGAECD)を提案し、関連手法とコミュニティ抽出の精度を比較することによって提案手法の有効性 を示しました。
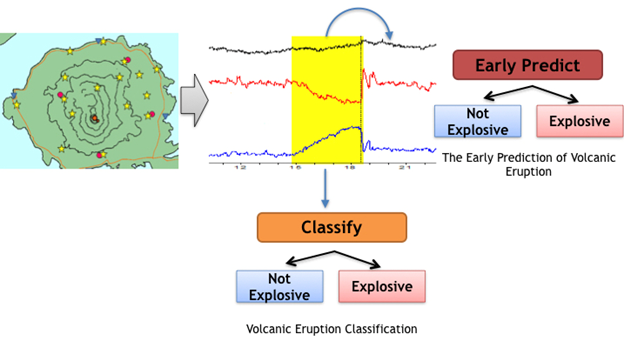
近年、音声認識、画像認識、自然言語処理などの様々な分野において深層学習が優れた性能を示しています。しかしながら、時系列データの学習に適用した例は比較的少ないです。この研究では時系列データとして、特に火山の観測機器から得られる時系列データに対して深層学習を適用しました。火山の観測機器から得られる時系列データは現在と将来の噴火と大きな関係があります。しかしデータは複雑で、専門家にとっても分析は容易ではありません。我々は火山噴火分類と火山噴火予測の二つの問題に注目しました。 前者(火山噴火分類)の目標は、100分間の時系列データからその100分間の火山の状態(噴火か否か)を認識することです。また後者(火山噴火予測)の目標は、100分間の時系列データから兆候を認識してその直後の60分間の火山の状態(噴火か否か)を予測することです。 複数モーダルを融合した提案手法であるVolNetは畳み込みニューラルネットワーク(CNN)に基づいて火山噴火分類を行い、F-scoreで90%の精度を達成しました。火山噴火予測については、Attentional Stacked Long Short-Term Memoryに基づく提案手法のPredictNetはsensitivityが66%、また警告システムでの一番危険度の高いカテゴリでの予測精度が64%と高い性能を示しています。我々は火山の研究者との協力のもと、火山に関する最大級の規模と質の時系列データを用いた実験によって、提案手法の有効性を示しています。
リンクマイニング
ネット上の様々なソーシャルサイト(delicious, twitter,...)は、今や情報共 有やコミュニケーションのインフラとして必要不可欠なものになっています。 このようなサイトを含め、ネット上で世界中のユーザが発信する膨大な情報を 有効活用するための試みが幅広く行われています。村田研究室では、ネット上 の情報のネットワーク構造に注目し、関連する要素の発見(コミュニティ抽出) や、要素の重要性の判定(ランキング、スパム検出)、将来のネットワーク構造 の推定(リンク予測)などを行っています。
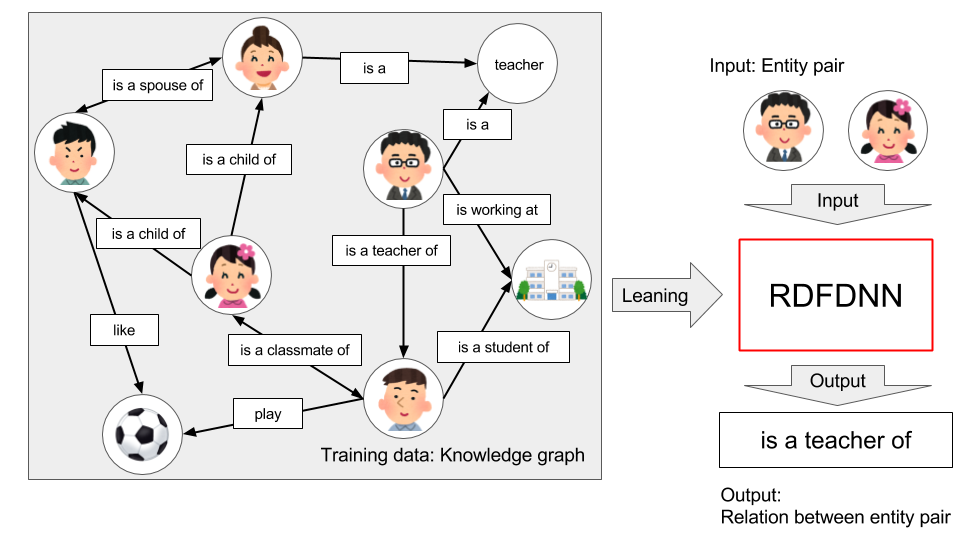
Knowledge Graph などの大規模なセマンティックWebを構築する上で、単語間の関係を予測することは重要です。Resource Description Framework(RDF)上の単語間の関係を高い精度で予測することを目標に、主語と目的語を入力として、それらの関係を出力するDeep Neural NetworkであるRDFDNNを構築しました。RDFDNNは、既存手法であるTransEやTransRよりも高精度な予測を実現できました。
論文、著者、会議名などの複数種類の頂点が結びついたheterogeneousネットワークで、一部の頂点のラベルが与えられたときに、残りの頂点を分類するtransductive classificationを高精度化するアプローチを提案しました。edge betweenness の定義を改良することで、最新の手法(GNetMine)よりも5%程度の精度向上を実現しました。
ネットワークからコミュニティを抽出する手法は数多く提案されていますが、トポロジーだけに注目するのではなく人間が持つ背景知識を用いることで、直観に合った結果にすることができます。背景知識を積極的に活用しようと試みる制約付きコミュニティ抽出手法として、モジュラリティを一般化して制約項を付加した制約付きハミルトニアンを最適化する手法がEatonらによって提案されていますが、速度が遅く大規模なネットワークには不向きです。本研究では、Eatonらが用いた擬似焼きなまし法ではなく、目的関数を高速に最適化するLouvain法を用いて、制約付きハミルトニアンを最適化し、制約付きコミュニティ抽出を高速化しています。
影響最大化問題は、社会ネットワーク上での情報伝搬や病気の感染において、情報や病気が最も広く拡散する頂点集合を見つける問題です。従来法の多くは中心性の高い頂点集合を求めていましたが、これでは影響を最大化する頂点集合は得られません。また厳密解を求めるのは静的ネットワークであっても計算量的に困難です。本研究では、動的ネットワークの影響最大化問題において、貪欲法とヒューリスティクスを用いることによって、厳密解と遜色ない精度の近似解を高速に求めることに成功しました。
現実の多くのソーシャルメディアは、様々な種類の頂点や辺を含んだヘテロなネットワークとして表現できます。例えばYouTubeはユーザ、タグ、動画の3種類の頂点から構成される3部ネットワークとみなすことができます。我々はこのようなネットワークから密な部分(コミュニティ)を抽出する手法を開発しました。
Signed networkは友人関係と敵対関係という二種類の辺を含んだネットワークです。我々はネットワーク分割の評価指標であるモジュラリティをSigned Networkに拡張しました。その結果、現実の社会ネットワークで見受けられるような派閥内派閥を見出すことに成功しました。
距離的に近い人は関係が密になりやすい傾向があります。そのような傾向を排除することによって、距離的に遠くに散らばった友人グループを見つけることができます。従来のコミュニティ評価指標を統合した新たな指標(Dist-Modularity)によって、地理的に散らばったコミュニティを見つけることができます。
この指標を用いて、テロリストのコミュニティを見つける試みも米国の研究者によってなされています。
現実世界における多くのネットワークはスケールフリー性をもっています。我々はそのようなスケールフリーネットワークからのコミュニティ抽出手法を開発しました。

偉大なスピーチは意味的に良い構造をしていると考えられます。与えられたスピーチの質を自動的に測るための第一歩として、我々はスピーチ中の単語の構造を、英単語の意味的関係を表す辞書であるWordNetと、単語感情極性対応表を用いて可視化しました。
- 2部ネットワークのコミュニティ抽出・可視化
- Webの掲示板と、それに書き込みをするユーザの関係は、2種類の頂点からなる2部ネットワークとして表現することができます。そのような2部ネットワークから密な部分ネットワーク(コミュニティ)を抽出することで、類似した内容の掲示板や、興味の似通ったユーザを見つけることができます。2種類の頂点のコミュニティを抽出し可視化するとともに、コミュニティ間の対応関係の尺度を定義しました。
- 村田 剛志, 池谷 智行, "異種頂点ネットワークで表現されたインターネットQA掲示板の分析と視覚化", 人工知能学会論文誌, Vol.23, No.5 pp.293-302, 2008.
-
- オンラインQAサイトにおけるリンク予測
- 人を頂点、その友人関係を辺として表すと、人間関係を社会ネットワークとして表すことができます。社会ネットワークの現在の構造から、将来の構造を予測することができたら、新たな人間関係の発展を見出したり重要人物を同定したりすることができます。ネットワーク上の頂点間の距離関数を改良することで、予測の精度を向上させました。
- Tsuyoshi Murata and Sakiko Moriyasu, “Link Prediction based on Structural Properties of Online Social Networks”, New Generation Computing, Vol.26, No.3, pp.245-257, 2008.
-
- 大規模ネットワークからの高速コミュニティ抽出
- 一般にネットワークから最適なコミュニティを抽出する計算はNP困難であり、ネットワークが大規模になるほど現実的な時間での計算が困難になります。コミュニティ抽出の手法は数多くありますが、比較的高速な手法と、高精度な手法を組み合わせることで、頂点数が100万程度の2部ネットワークでのコミュニティ抽出を可能にしました。
- 劉欣, 村田剛志, "Community Detection in Large-scale Bipartite Networks", 人工知能学会論文誌, Vol.25, No.1, pp.16-24, 2010.
-
- 異種頂点ネットワークのコミュニティ抽出の評価指標
- 与えられたネットワークを分割してコミュニティを抽出するにあたり、その分割の良さを測る指標として、Newman-Girvanのモジュラリティがあります。モジュラリティは非常に幅広く使われていますが、異種頂点ネットワークに対しては適切ではありません。モジュラリティの定義を2部ネットワークに拡張し、コミュニティの対応関係が1対多であるような分割も許す新たな評価指標を提案し実験を行いました。
- Tsuyoshi Murata and Tomoyuki Ikeya, "A New Modularity for Detecting One-to-Many Correspondence of Communities in Bipartite Networks", Advances in Complex Systems, World Scientific, Vol. 13, No. 1, pp.19-31, 2010.
- タイトル: K-Partite K-Uniform (ハイパー)ネットワークからのコミュニティ抽出
- 説明: 一般のK-Partite K-Uniform (ハイパー)ネットワークからのコミュニティ抽出の手法を提案しました。この手法は従来手法の欠点を克服するとともに、理解しやすさ、適合性、パラメータ設定の必要性、精度、スケーラビリティの点で望ましい性質を有しています。
-
 ポスターはここ
ポスターはここ
Web利用データのマイニング
ユーザがWebにアクセスすることで、アクセスログ、ブックマーク、検索語など、様々なデータが生じます。そのようなデータをもとに、ユーザの興味を抽出したりする研究を行っています。- Web閲覧履歴からのユーザ興味の抽出
- ユーザが閲覧したサイトと、検索時に入力した検索語からなるネットワーク(サイト-キーワードグラフ)の頂点のランキングを行い、中心的な部分を抽出することで、そのユーザの興味を推定する手法を考案し、8,000人程度のユーザデータを用いて実験を行いました。
- 村田剛志, 齋藤皓太:サイト・キーワードグラフを用いたWebユーザの興味の抽出と視覚化, 知能と情報, Vol.18, No.5, pp.701-710, 2006.
-